384 lines
23 KiB
Markdown
384 lines
23 KiB
Markdown
|
|
---
|
||
|
|
comments: true
|
||
|
|
description: YOLO26 from Ultralytics delivers faster, simpler, end-to-end NMS-free object detection optimized for edge and low-power devices.
|
||
|
|
keywords: YOLO26, Ultralytics YOLO, object detection, end-to-end NMS-free, simplified architecture, computer vision, AI, machine learning, edge AI, low power devices, quantization, real-time inference
|
||
|
|
---
|
||
|
|
|
||
|
|
# Ultralytics YOLO26
|
||
|
|
|
||
|
|
## Overview
|
||
|
|
|
||
|
|
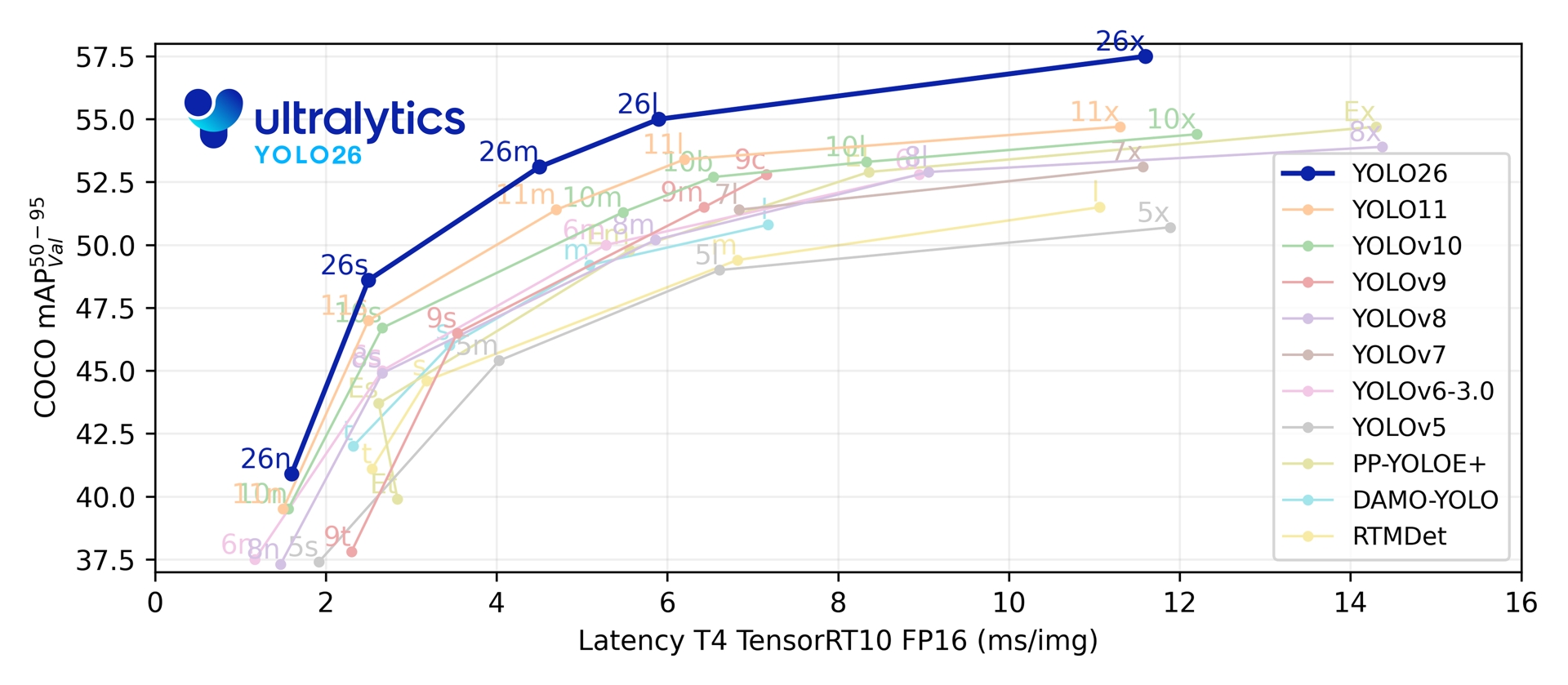
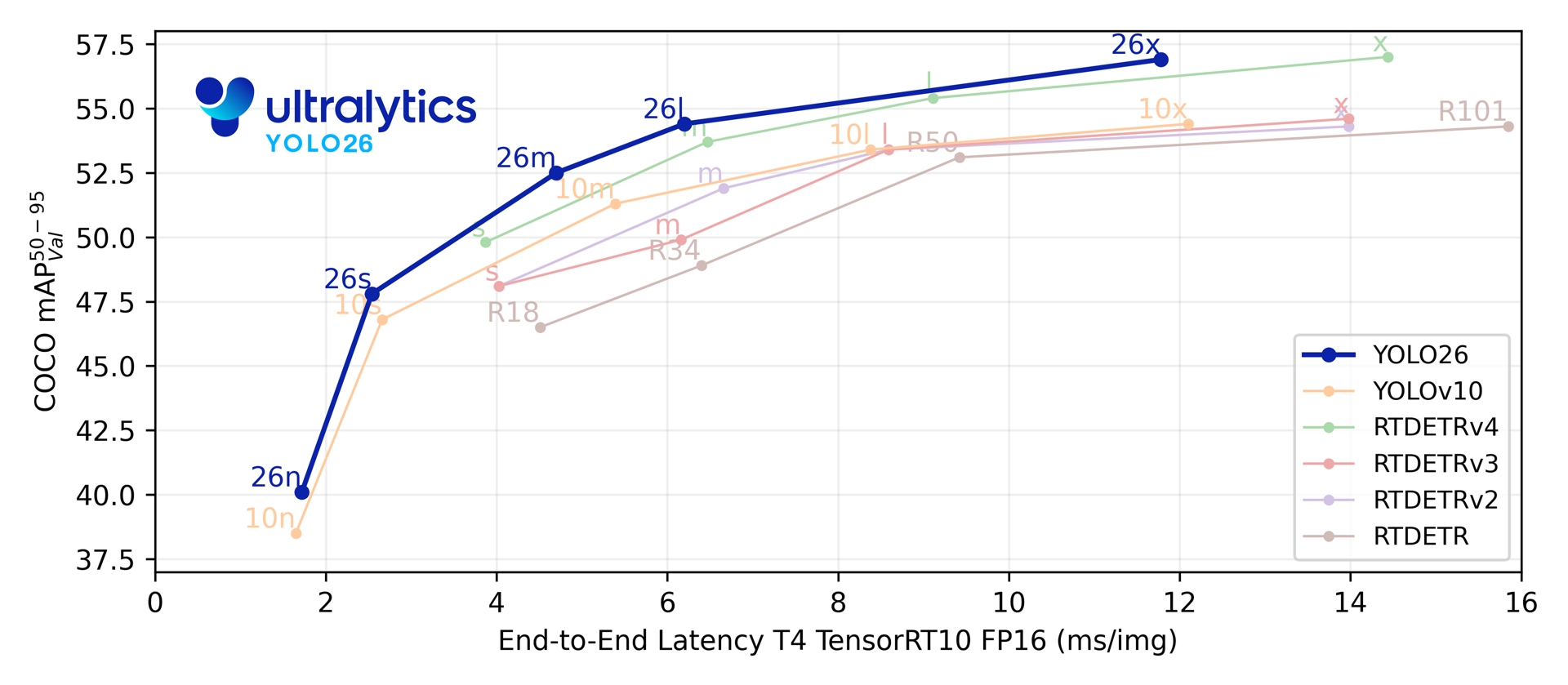
[Ultralytics](https://www.ultralytics.com/) YOLO26 is the latest evolution in the YOLO series of real-time object detectors, engineered from the ground up for **edge and low-power devices**. It introduces a streamlined design that removes unnecessary complexity while integrating targeted innovations to deliver faster, lighter, and more accessible deployment.
|
||
|
|
|
||
|
|
|
||
|
|
|
||
|
|
!!! tip "Try on Ultralytics Platform"
|
||
|
|
|
||
|
|
Explore and run YOLO26 models directly on [Ultralytics Platform](https://platform.ultralytics.com/ultralytics/yolo26).
|
||
|
|
|
||
|
|
The architecture of YOLO26 is guided by three core principles:
|
||
|
|
|
||
|
|
- **Simplicity:** YOLO26 is a **native end-to-end model**, producing predictions directly without the need for non-maximum suppression (NMS). By eliminating this post-processing step, inference becomes faster, lighter, and easier to deploy in real-world systems. This breakthrough approach was first pioneered in [YOLOv10](../models/yolov10.md) by Ao Wang at Tsinghua University and has been further advanced in YOLO26.
|
||
|
|
- **Deployment Efficiency:** The end-to-end design cuts out an entire stage of the pipeline, dramatically simplifying integration, reducing latency, and making deployment more robust across diverse environments.
|
||
|
|
- **Training Innovation:** YOLO26 introduces the **MuSGD optimizer**, a hybrid of [SGD](https://docs.pytorch.org/docs/stable/generated/torch.optim.SGD.html) and [Muon](https://arxiv.org/abs/2502.16982) — inspired by Moonshot AI's [Kimi K2](https://www.kimi.com/) breakthroughs in LLM training. This optimizer brings enhanced stability and faster convergence, transferring optimization advances from language models into computer vision.
|
||
|
|
- **Task-Specific Optimizations:** YOLO26 introduces targeted improvements for specialized tasks, including semantic segmentation loss and multi-scale proto modules for **Segmentation**, Residual Log-Likelihood Estimation (RLE) for high-precision **Pose** estimation, and optimized decoding with angle loss to resolve boundary issues in **OBB**.
|
||
|
|
|
||
|
|
Together, these innovations deliver a model family that achieves higher accuracy on small objects, provides seamless deployment, and runs **up to 43% faster on CPUs** — making YOLO26 one of the most practical and deployable YOLO models to date for resource-constrained environments.
|
||
|
|
|
||
|
|
## Key Features
|
||
|
|
|
||
|
|
- **DFL Removal**
|
||
|
|
The Distribution Focal Loss (DFL) module, while effective, often complicated export and limited hardware compatibility. YOLO26 removes DFL entirely, simplifying inference and broadening support for **edge and low-power devices**.
|
||
|
|
|
||
|
|
- **End-to-End NMS-Free Inference**
|
||
|
|
Unlike traditional detectors that rely on NMS as a separate post-processing step, YOLO26 is **natively end-to-end**. Predictions are generated directly, reducing latency and making integration into production systems faster, lighter, and more reliable.
|
||
|
|
|
||
|
|
- **ProgLoss + STAL**
|
||
|
|
Improved loss functions increase detection accuracy, with notable improvements in **small-object recognition**, a critical requirement for IoT, robotics, aerial imagery, and other edge applications.
|
||
|
|
|
||
|
|
- **MuSGD Optimizer**
|
||
|
|
A new hybrid optimizer that combines [SGD](https://docs.pytorch.org/docs/stable/generated/torch.optim.SGD.html) with [Muon](https://arxiv.org/abs/2502.16982). Inspired by Moonshot AI's [Kimi K2](https://www.kimi.com/), MuSGD introduces advanced optimization methods from LLM training into computer vision, enabling more stable training and faster convergence.
|
||
|
|
|
||
|
|
- **Up to 43% Faster CPU Inference**
|
||
|
|
Specifically optimized for edge computing, YOLO26 delivers significantly faster CPU inference, ensuring real-time performance on devices without GPUs.
|
||
|
|
|
||
|
|
- **Instance Segmentation Enhancements**
|
||
|
|
Introduces semantic segmentation loss to improve model convergence and an upgraded proto module that leverages multi-scale information for superior mask quality.
|
||
|
|
|
||
|
|
- **Precision Pose Estimation**
|
||
|
|
Integrates [Residual Log-Likelihood Estimation](https://arxiv.org/abs/2107.11291) (RLE) for more accurate keypoint localization and optimizes the decoding process for increased inference speed.
|
||
|
|
|
||
|
|
- **Refined OBB Decoding**
|
||
|
|
Introduces a specialized angle loss to improve detection accuracy for square-shaped objects and optimizes OBB decoding to resolve boundary discontinuity issues.
|
||
|
|
|
||
|
|
|
||
|
|
|
||
|
|
---
|
||
|
|
|
||
|
|
## Supported Tasks and Modes
|
||
|
|
|
||
|
|
YOLO26 builds upon the versatile model range established by earlier Ultralytics YOLO releases, offering enhanced support across various computer vision tasks:
|
||
|
|
|
||
|
|
| Model | Filenames | Task | Inference | Validation | Training | Export |
|
||
|
|
| ----------- | ----------------------------------------------------------------------------------------- | -------------------------------------------- | --------- | ---------- | -------- | ------ |
|
||
|
|
| YOLO26 | `yolo26n.pt` `yolo26s.pt` `yolo26m.pt` `yolo26l.pt` `yolo26x.pt` | [Detection](../tasks/detect.md) | ✅ | ✅ | ✅ | ✅ |
|
||
|
|
| YOLO26-seg | `yolo26n-seg.pt` `yolo26s-seg.pt` `yolo26m-seg.pt` `yolo26l-seg.pt` `yolo26x-seg.pt` | [Instance Segmentation](../tasks/segment.md) | ✅ | ✅ | ✅ | ✅ |
|
||
|
|
| YOLO26-pose | `yolo26n-pose.pt` `yolo26s-pose.pt` `yolo26m-pose.pt` `yolo26l-pose.pt` `yolo26x-pose.pt` | [Pose/Keypoints](../tasks/pose.md) | ✅ | ✅ | ✅ | ✅ |
|
||
|
|
| YOLO26-obb | `yolo26n-obb.pt` `yolo26s-obb.pt` `yolo26m-obb.pt` `yolo26l-obb.pt` `yolo26x-obb.pt` | [Oriented Detection](../tasks/obb.md) | ✅ | ✅ | ✅ | ✅ |
|
||
|
|
| YOLO26-cls | `yolo26n-cls.pt` `yolo26s-cls.pt` `yolo26m-cls.pt` `yolo26l-cls.pt` `yolo26x-cls.pt` | [Classification](../tasks/classify.md) | ✅ | ✅ | ✅ | ✅ |
|
||
|
|
|
||
|
|
This unified framework ensures YOLO26 is applicable across real-time detection, segmentation, classification, pose estimation, and oriented object detection — all with training, validation, inference, and export support.
|
||
|
|
|
||
|
|
---
|
||
|
|
|
||
|
|
## Performance Metrics
|
||
|
|
|
||
|
|
!!! tip "Performance"
|
||
|
|
|
||
|
|
=== "Detection (COCO)"
|
||
|
|
|
||
|
|
See [Detection Docs](../tasks/detect.md) for usage examples with these models trained on [COCO](../datasets/detect/coco.md), which include 80 pretrained classes.
|
||
|
|
|
||
|
|
--8<-- "docs/macros/yolo-det-perf.md"
|
||
|
|
|
||
|
|
=== "Segmentation (COCO)"
|
||
|
|
|
||
|
|
See [Segmentation Docs](../tasks/segment.md) for usage examples with these models trained on [COCO](../datasets/segment/coco.md), which include 80 pretrained classes.
|
||
|
|
|
||
|
|
--8<-- "docs/macros/yolo-seg-perf.md"
|
||
|
|
|
||
|
|
=== "Classification (ImageNet)"
|
||
|
|
|
||
|
|
See [Classification Docs](../tasks/classify.md) for usage examples with these models trained on [ImageNet](../datasets/classify/imagenet.md), which include 1000 pretrained classes.
|
||
|
|
|
||
|
|
--8<-- "docs/macros/yolo-cls-perf.md"
|
||
|
|
|
||
|
|
=== "Pose (COCO)"
|
||
|
|
|
||
|
|
See [Pose Estimation Docs](../tasks/pose.md) for usage examples with these models trained on [COCO](../datasets/pose/coco.md), which include 1 pretrained class, 'person'.
|
||
|
|
|
||
|
|
--8<-- "docs/macros/yolo-pose-perf.md"
|
||
|
|
|
||
|
|
=== "OBB (DOTAv1)"
|
||
|
|
|
||
|
|
See [Oriented Detection Docs](../tasks/obb.md) for usage examples with these models trained on [DOTAv1](../datasets/obb/dota-v2.md#dota-v10), which include 15 pretrained classes.
|
||
|
|
|
||
|
|
--8<-- "docs/macros/yolo-obb-perf.md"
|
||
|
|
|
||
|
|
---
|
||
|
|
|
||
|
|
## Usage Examples
|
||
|
|
|
||
|
|
This section provides simple YOLO26 training and inference examples. For full documentation on these and other [modes](../modes/index.md), see the [Predict](../modes/predict.md), [Train](../modes/train.md), [Val](../modes/val.md), and [Export](../modes/export.md) docs pages.
|
||
|
|
|
||
|
|
Note that the example below is for YOLO26 [Detect](../tasks/detect.md) models for [object detection](https://www.ultralytics.com/glossary/object-detection). For additional supported tasks, see the [Segment](../tasks/segment.md), [Classify](../tasks/classify.md), [OBB](../tasks/obb.md), and [Pose](../tasks/pose.md) docs.
|
||
|
|
|
||
|
|
!!! example
|
||
|
|
|
||
|
|
=== "Python"
|
||
|
|
|
||
|
|
[PyTorch](https://www.ultralytics.com/glossary/pytorch) pretrained `*.pt` models as well as configuration `*.yaml` files can be passed to the `YOLO()` class to create a model instance in Python:
|
||
|
|
|
||
|
|
```python
|
||
|
|
from ultralytics import YOLO
|
||
|
|
|
||
|
|
# Load a COCO-pretrained YOLO26n model
|
||
|
|
model = YOLO("yolo26n.pt")
|
||
|
|
|
||
|
|
# Train the model on the COCO8 example dataset for 100 epochs
|
||
|
|
results = model.train(data="coco8.yaml", epochs=100, imgsz=640)
|
||
|
|
|
||
|
|
# Run inference with the YOLO26n model on the 'bus.jpg' image
|
||
|
|
results = model("path/to/bus.jpg")
|
||
|
|
```
|
||
|
|
|
||
|
|
=== "CLI"
|
||
|
|
|
||
|
|
CLI commands are available to directly run the models:
|
||
|
|
|
||
|
|
```bash
|
||
|
|
# Load a COCO-pretrained YOLO26n model and train it on the COCO8 example dataset for 100 epochs
|
||
|
|
yolo train model=yolo26n.pt data=coco8.yaml epochs=100 imgsz=640
|
||
|
|
|
||
|
|
# Load a COCO-pretrained YOLO26n model and run inference on the 'bus.jpg' image
|
||
|
|
yolo predict model=yolo26n.pt source=path/to/bus.jpg
|
||
|
|
```
|
||
|
|
|
||
|
|
!!! note "Dual-Head Architecture"
|
||
|
|
|
||
|
|
YOLO26 features a **dual-head architecture** that provides flexibility for different deployment scenarios:
|
||
|
|
|
||
|
|
- **One-to-One Head (Default)**: Produces end-to-end predictions without NMS, outputting `(N, 300, 6)` with a maximum of 300 detections per image. This head is optimized for fast inference and simplified deployment.
|
||
|
|
- **One-to-Many Head**: Generates traditional YOLO outputs requiring NMS post-processing, outputting `(N, nc + 4, 8400)` where `nc` is the number of classes. This head typically achieves slightly higher accuracy at the cost of additional processing.
|
||
|
|
|
||
|
|
You can switch between heads during export, prediction, or validation:
|
||
|
|
|
||
|
|
=== "Python"
|
||
|
|
|
||
|
|
```python
|
||
|
|
from ultralytics import YOLO
|
||
|
|
|
||
|
|
model = YOLO("yolo26n.pt")
|
||
|
|
|
||
|
|
# Use one-to-one head (default, no NMS required)
|
||
|
|
results = model.predict("image.jpg") # inference
|
||
|
|
metrics = model.val(data="coco.yaml") # validation
|
||
|
|
model.export(format="onnx") # export
|
||
|
|
|
||
|
|
# Use one-to-many head (requires NMS)
|
||
|
|
results = model.predict("image.jpg", end2end=False) # inference
|
||
|
|
metrics = model.val(data="coco.yaml", end2end=False) # validation
|
||
|
|
model.export(format="onnx", end2end=False) # export
|
||
|
|
```
|
||
|
|
|
||
|
|
=== "CLI"
|
||
|
|
|
||
|
|
```bash
|
||
|
|
# Use one-to-one head (default, no NMS required)
|
||
|
|
yolo predict model=yolo26n.pt source=image.jpg
|
||
|
|
yolo val model=yolo26n.pt data=coco.yaml
|
||
|
|
yolo export model=yolo26n.pt format=onnx
|
||
|
|
|
||
|
|
# Use one-to-many head (requires NMS)
|
||
|
|
yolo predict model=yolo26n.pt source=image.jpg end2end=False
|
||
|
|
yolo val model=yolo26n.pt data=coco.yaml end2end=False
|
||
|
|
yolo export model=yolo26n.pt format=onnx end2end=False
|
||
|
|
```
|
||
|
|
|
||
|
|
The choice depends on your deployment requirements: use the one-to-one head for maximum speed and simplicity, or the one-to-many head when accuracy is the top priority.
|
||
|
|
|
||
|
|
## YOLOE-26: Open-Vocabulary Instance Segmentation
|
||
|
|
|
||
|
|
YOLOE-26 integrates the high-performance YOLO26 architecture with the open-vocabulary capabilities of the [YOLOE](yoloe.md) series. It enables real-time detection and segmentation of any object class using **text prompts**, **visual prompts**, or a **prompt-free mode** for zero-shot inference, effectively removing the constraints of fixed-category training.
|
||
|
|
|
||
|
|
By leveraging YOLO26's **NMS-free, end-to-end design**, YOLOE-26 delivers fast open-world inference. This makes it a powerful solution for edge applications in dynamic environments where the objects of interest represent a broad and evolving vocabulary.
|
||
|
|
|
||
|
|
!!! tip "Performance"
|
||
|
|
|
||
|
|
=== "Text/Visual Prompts"
|
||
|
|
|
||
|
|
See [YOLOE Docs](./yoloe.md) for usage examples with these models trained on [Objects365v1](https://opendatalab.com/OpenDataLab/Objects365_v1), [GQA](https://cs.stanford.edu/people/dorarad/gqa/about.html) and [Flickr30k](https://shannon.cs.illinois.edu/DenotationGraph/) datasets.
|
||
|
|
|
||
|
|
| Model | size<br><sup>(pixels)</sup> | Prompt Type | mAP<sup>minival<br>50-95(e2e)</sup> | mAP<sup>minival<br>50-95</sup> | mAP<sub>r</sub> | mAP<sub>c</sub> | mAP<sub>f</sub> | params<br><sup>(M)</sup> | FLOPs<br><sup>(B)</sup> |
|
||
|
|
|---------------|-----------------------------|-------------|-------------------------------------|----------------------------|-----------------|-----------------|-----------------|--------------------------|-------------------------|
|
||
|
|
| [YOLOE-26n-seg](https://github.com/ultralytics/assets/releases/download/v8.4.0/yoloe-26n-seg.pt) | 640 | Text/Visual | 23.7 / 20.9 | 24.7 / 21.9 | 20.5 / 17.6 | 24.1 / 22.3 | 26.1 / 22.4 | 4.8 | 6.0 |
|
||
|
|
| [YOLOE-26s-seg](https://github.com/ultralytics/assets/releases/download/v8.4.0/yoloe-26s-seg.pt) | 640 | Text/Visual | 29.9 / 27.1 | 30.8 / 28.6 | 23.9 / 25.1 | 29.6 / 27.8 | 33.0 / 29.9 | 13.1 | 21.7 |
|
||
|
|
| [YOLOE-26m-seg](https://github.com/ultralytics/assets/releases/download/v8.4.0/yoloe-26m-seg.pt) | 640 | Text/Visual | 35.4 / 31.3 | 35.4 / 33.9 | 31.1 / 33.4 | 34.7 / 34.0 | 36.9 / 33.8 | 27.9 | 70.1 |
|
||
|
|
| [YOLOE-26l-seg](https://github.com/ultralytics/assets/releases/download/v8.4.0/yoloe-26l-seg.pt) | 640 | Text/Visual | 36.8 / 33.7 | 37.8 / 36.3 | 35.1 / 37.6 | 37.6 / 36.2 | 38.5 / 36.1 | 32.3 | 88.3 |
|
||
|
|
| [YOLOE-26x-seg](https://github.com/ultralytics/assets/releases/download/v8.4.0/yoloe-26x-seg.pt) | 640 | Text/Visual | 39.5 / 36.2 | 40.6 / 38.5 | 37.4 / 35.3 | 40.9 / 38.8 | 41.0 / 38.8 | 69.9 | 196.7 |
|
||
|
|
|
||
|
|
|
||
|
|
=== "Prompt-free"
|
||
|
|
|
||
|
|
See [YOLOE Docs](./yoloe.md) for usage examples with these models trained on [Objects365v1](https://opendatalab.com/OpenDataLab/Objects365_v1), [GQA](https://cs.stanford.edu/people/dorarad/gqa/about.html) and [Flickr30k](https://shannon.cs.illinois.edu/DenotationGraph/) datasets.
|
||
|
|
|
||
|
|
| Model | size<br><sup>(pixels)</sup> | mAP<sup>minival<br>50-95(e2e)</sup> | mAP<sup>minival<br>50(e2e)</sup> | params<br><sup>(M)</sup> | FLOPs<br><sup>(B)</sup> |
|
||
|
|
|------------------|-----------------------------|-------------------------------------|------------------------------|--------------------------|-------------------------|
|
||
|
|
| [YOLOE-26n-seg-pf](https://github.com/ultralytics/assets/releases/download/v8.4.0/yoloe-26n-seg-pf.pt) | 640 | 16.6 | 22.7 | 6.5 | 15.8 |
|
||
|
|
| [YOLOE-26s-seg-pf](https://github.com/ultralytics/assets/releases/download/v8.4.0/yoloe-26s-seg-pf.pt) | 640 | 21.4 | 28.6 | 16.2 | 35.5 |
|
||
|
|
| [YOLOE-26m-seg-pf](https://github.com/ultralytics/assets/releases/download/v8.4.0/yoloe-26m-seg-pf.pt) | 640 | 25.7 | 33.6 | 36.2 | 122.1 |
|
||
|
|
| [YOLOE-26l-seg-pf](https://github.com/ultralytics/assets/releases/download/v8.4.0/yoloe-26l-seg-pf.pt) | 640 | 27.2 | 35.4 | 40.6 | 140.4 |
|
||
|
|
| [YOLOE-26x-seg-pf](https://github.com/ultralytics/assets/releases/download/v8.4.0/yoloe-26x-seg-pf.pt) | 640 | 29.9 | 38.7 | 86.3 | 314.4 |
|
||
|
|
|
||
|
|
### Usage Example
|
||
|
|
|
||
|
|
YOLOE-26 supports both text-based and visual prompting. Using prompts is straightforward—just pass them through the `predict` method as shown below:
|
||
|
|
|
||
|
|
!!! example
|
||
|
|
|
||
|
|
=== "Text Prompt"
|
||
|
|
|
||
|
|
Text prompts allow you to specify the classes that you wish to detect through textual descriptions. The following code shows how you can use YOLOE-26 to detect people and buses in an image:
|
||
|
|
|
||
|
|
```python
|
||
|
|
from ultralytics import YOLO
|
||
|
|
|
||
|
|
# Initialize model
|
||
|
|
model = YOLO("yoloe-26l-seg.pt") # or select yoloe-26s/m-seg.pt for different sizes
|
||
|
|
|
||
|
|
# Set text prompt to detect person and bus. You only need to do this once after you load the model.
|
||
|
|
names = ["person", "bus"]
|
||
|
|
model.set_classes(names, model.get_text_pe(names))
|
||
|
|
|
||
|
|
# Run detection on the given image
|
||
|
|
results = model.predict("path/to/image.jpg")
|
||
|
|
|
||
|
|
# Show results
|
||
|
|
results[0].show()
|
||
|
|
```
|
||
|
|
|
||
|
|
=== "Visual Prompt"
|
||
|
|
|
||
|
|
Visual prompts allow you to guide the model by showing it visual examples of the target classes, rather than describing them in text.
|
||
|
|
|
||
|
|
```python
|
||
|
|
import numpy as np
|
||
|
|
|
||
|
|
from ultralytics import YOLO
|
||
|
|
from ultralytics.models.yolo.yoloe import YOLOEVPSegPredictor
|
||
|
|
|
||
|
|
# Initialize model
|
||
|
|
model = YOLO("yoloe-26l-seg.pt")
|
||
|
|
|
||
|
|
# Define visual prompts using bounding boxes and their corresponding class IDs.
|
||
|
|
# Each box highlights an example of the object you want the model to detect.
|
||
|
|
visual_prompts = dict(
|
||
|
|
bboxes=np.array(
|
||
|
|
[
|
||
|
|
[221.52, 405.8, 344.98, 857.54], # Box enclosing person
|
||
|
|
[120, 425, 160, 445], # Box enclosing glasses
|
||
|
|
],
|
||
|
|
),
|
||
|
|
cls=np.array(
|
||
|
|
[
|
||
|
|
0, # ID to be assigned for person
|
||
|
|
1, # ID to be assigned for glasses
|
||
|
|
]
|
||
|
|
),
|
||
|
|
)
|
||
|
|
|
||
|
|
# Run inference on an image, using the provided visual prompts as guidance
|
||
|
|
results = model.predict(
|
||
|
|
"ultralytics/assets/bus.jpg",
|
||
|
|
visual_prompts=visual_prompts,
|
||
|
|
predictor=YOLOEVPSegPredictor,
|
||
|
|
)
|
||
|
|
|
||
|
|
# Show results
|
||
|
|
results[0].show()
|
||
|
|
```
|
||
|
|
|
||
|
|
=== "Prompt free"
|
||
|
|
|
||
|
|
YOLOE-26 includes prompt-free variants that come with a built-in vocabulary. These models don't require any prompts and work like traditional YOLO models. Instead of relying on user-provided labels or visual examples, they detect objects from a [predefined list of 4,585 classes](https://github.com/xinyu1205/recognize-anything/blob/main/ram/data/ram_tag_list.txt) based on the tag set used by the [Recognize Anything Model Plus (RAM++)](https://arxiv.org/abs/2310.15200).
|
||
|
|
|
||
|
|
```python
|
||
|
|
from ultralytics import YOLO
|
||
|
|
|
||
|
|
# Initialize model
|
||
|
|
model = YOLO("yoloe-26l-seg-pf.pt")
|
||
|
|
|
||
|
|
# Run prediction. No prompts required.
|
||
|
|
results = model.predict("path/to/image.jpg")
|
||
|
|
|
||
|
|
# Show results
|
||
|
|
results[0].show()
|
||
|
|
```
|
||
|
|
|
||
|
|
For a deep dive into prompting techniques, training from scratch, and full usage examples, visit the **[YOLOE Documentation](yoloe.md)**.
|
||
|
|
|
||
|
|
## Citations and Acknowledgments
|
||
|
|
|
||
|
|
!!! tip "Ultralytics YOLO26 Publication"
|
||
|
|
|
||
|
|
Ultralytics has not published a formal research paper for YOLO26 due to the rapidly evolving nature of the models. Instead, we focus on delivering cutting-edge models and making them easy to use. For the latest updates on YOLO features, architectures, and usage, visit our [GitHub repository](https://github.com/ultralytics/ultralytics) and [documentation](https://docs.ultralytics.com/).
|
||
|
|
|
||
|
|
If you use YOLO26 or other Ultralytics software in your work, please cite it as:
|
||
|
|
|
||
|
|
!!! quote ""
|
||
|
|
|
||
|
|
=== "BibTeX"
|
||
|
|
|
||
|
|
```bibtex
|
||
|
|
@software{yolo26_ultralytics,
|
||
|
|
author = {Glenn Jocher and Jing Qiu},
|
||
|
|
title = {Ultralytics YOLO26},
|
||
|
|
version = {26.0.0},
|
||
|
|
year = {2026},
|
||
|
|
url = {https://github.com/ultralytics/ultralytics},
|
||
|
|
orcid = {0000-0001-5950-6979, 0000-0003-3783-7069},
|
||
|
|
license = {AGPL-3.0}
|
||
|
|
}
|
||
|
|
```
|
||
|
|
|
||
|
|
DOI pending. YOLO26 is available under [AGPL-3.0](https://github.com/ultralytics/ultralytics/blob/main/LICENSE) and [Enterprise](https://www.ultralytics.com/license) licenses.
|
||
|
|
|
||
|
|
---
|
||
|
|
|
||
|
|
## FAQ
|
||
|
|
|
||
|
|
### What are the key improvements in YOLO26 compared to YOLO11?
|
||
|
|
|
||
|
|
- **DFL Removal**: Simplifies export and expands edge compatibility
|
||
|
|
- **End-to-End NMS-Free Inference**: Eliminates NMS for faster, simpler deployment
|
||
|
|
- **ProgLoss + STAL**: Boosts accuracy, especially on small objects
|
||
|
|
- **MuSGD Optimizer**: Combines SGD and Muon (inspired by Moonshot's Kimi K2) for more stable, efficient training
|
||
|
|
- **Up to 43% Faster CPU Inference**: Major performance gains for CPU-only devices
|
||
|
|
|
||
|
|
### What tasks does YOLO26 support?
|
||
|
|
|
||
|
|
YOLO26 is a **unified model family**, providing end-to-end support for multiple computer vision tasks:
|
||
|
|
|
||
|
|
- [Object Detection](../tasks/detect.md)
|
||
|
|
- [Instance Segmentation](../tasks/segment.md)
|
||
|
|
- [Image Classification](../tasks/classify.md)
|
||
|
|
- [Pose Estimation](../tasks/pose.md)
|
||
|
|
- [Oriented Object Detection (OBB)](../tasks/obb.md)
|
||
|
|
|
||
|
|
Each size variant (n, s, m, l, x) supports all tasks, plus open-vocabulary versions via [YOLOE-26](#yoloe-26-open-vocabulary-instance-segmentation).
|
||
|
|
|
||
|
|
### Why is YOLO26 optimized for edge deployment?
|
||
|
|
|
||
|
|
YOLO26 delivers **state-of-the-art edge performance** with:
|
||
|
|
|
||
|
|
- Up to 43% faster CPU inference
|
||
|
|
- Reduced model size and memory footprint
|
||
|
|
- Architecture simplified for compatibility (no DFL, no NMS)
|
||
|
|
- Flexible export formats including TensorRT, ONNX, CoreML, TFLite, and OpenVINO
|
||
|
|
|
||
|
|
### How do I get started with YOLO26?
|
||
|
|
|
||
|
|
YOLO26 models were released on January 14, 2026, and are available for download. Install or update the `ultralytics` package and load a model:
|
||
|
|
|
||
|
|
```python
|
||
|
|
from ultralytics import YOLO
|
||
|
|
|
||
|
|
# Load a pretrained YOLO26 nano model
|
||
|
|
model = YOLO("yolo26n.pt")
|
||
|
|
|
||
|
|
# Run inference on an image
|
||
|
|
results = model("image.jpg")
|
||
|
|
```
|
||
|
|
|
||
|
|
See the [Usage Examples](#usage-examples) section for training, validation, and export instructions.
|